SQL 优化的书有哪些推荐?
发表时间:2024-02-28 00:19:37
文章作者:佚名
浏览次数:
有一定的基础,数据库是oracle的,电信行业……求推荐sql优化的书籍。谢谢!








Oracle 官方 051 教材.
我见过很多人写的SQL性能很差,完全是因为连SQL基本语法都没搞明白.
只谈SQL本身是优化不出来多少东西的。
首先,设计数据库时就要考虑查询及优化,有必要就用冗余换效率。
其次,对业务的理解和数据库特性的使用。
最后,深入理解关系代数与SQL语法。
数据库优化一方面是找出系统的瓶颈,提高MySQL数据库的整体性能,而另一方面需要合理的结构设计和参数调整,以提高用户的相应速度,同时还要尽可能的节约系统资源,以便让系统提供更大的负荷.
高性能MySQL是MySQL领域的经典之作,拥有广泛的影响力,学习MySQL的朋友都应该有所耳闻,所以我就不作过多介绍,唯一的建议就是仔细看、认真看、多看几遍,我每次看都会有不小的收获。这就是一本虽然书很厚,但是需要一页一页、一行一行都认真看的书。
如果认真学习完前面几本书,基本上都已经对MySQL掌握得不错了,但是,如果不了解如何设计一个好的索引,仍然不能成为牛逼的DBA,牛逼的DBA和不牛逼的DBA,一半就是看对索引的掌握情况, 《数据库索引设计与优化》就是从普通DBA走向牛逼DBA的捷径,这本书在淘宝内部非常推崇,但是在中国名气却不是很大,很多人不了解。这本书也是今年夏天刚有中文版本的,非常值得入手以后跟着练习,虽然知道的人不多,豆瓣上也几乎没有什么评价,但是,强烈推荐、吐血推荐!
学习MySQL的使用,首推姜承尧的《MySQL技术内幕:InnoDB存储引擎》,当然不是因为姜sir是我的经理才推荐这本书。这本书确实做到了由渐入深、深入浅出,是中国人写的最赞的MySQL技术书籍,符合国人的思维方式和阅读习惯,而且,这本书简直就是面试宝典,对于近期有求职MySQL相关岗位的朋友,可以认真阅读,对找工作有很大的帮助。当然,也有人说这本书入门难度较大,这个就自己取舍了,个人建议就以这本书入门即可,有不懂的地方可以求助官方手册和google。
我刚开始学习MySQL的时候误区就是,没有好好阅读MySQL的官方手册。例如,我刚开始很难理解InnoDB的锁,尤其是各个情况下如何加锁,这个问题在我师弟进入百度做DBA时,也困扰了他一阵子,我们两还讨论来讨论去,其实,MySQL官方手册已经写得清清楚楚,什么样的SQL语句加什么样的锁,当然,MySQL的官方手册非常庞大,一时半会很难看完,建议先看InnoDB相关的部分。
http://dev.mysql.com/doc/refman/5.7/en/innodb-storage-engine.html
《MySQL排错指南》是2015年夏天引入中国的书籍,这本书可以说是DBA速成指南,介绍的内容其实比较简单,但是也非常实用,对于DBA这个讲究经验的工种,这本书就是传授经验的,可能对有较多工作经验的DBA来说,这本书基本没有什么用,但是,对于刚入职场的新人,或学校里的学生,这本书会有较大的帮助,非常推荐。
插句题外话作为程序员在面试的时候必须要知道的优化技巧:
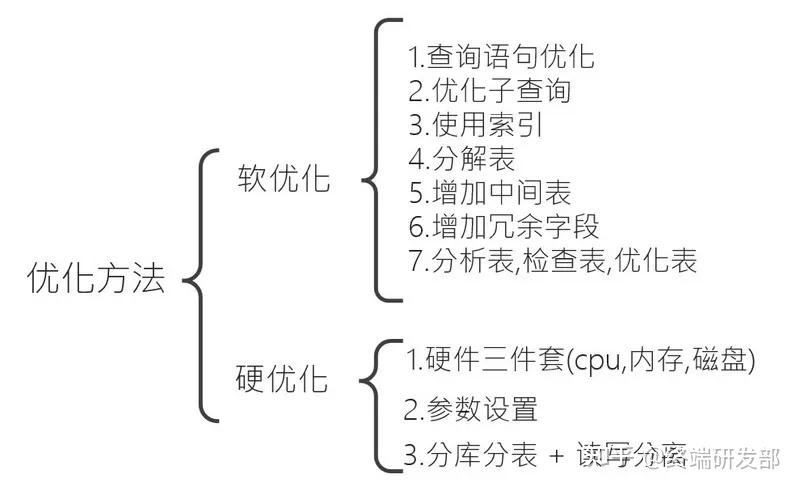
笔者将优化分为了两大类,软优化和硬优化,软优化一般是操作数据库即可,而硬优化则是操作服务器硬件及参数设置.
1.首先我们可以用EXPLAIN或DESCRIBE(简写:DESC)命令分析一条查询语句的执行信息.
2.例:
DESC SELECT * FROM `user`
显示:
其中会显示索引和查询数据读取数据条数等信息.
在MySQL中,尽量使用JOIN来代替子查询.因为子查询需要嵌套查询,嵌套查询时会建立一张临时表,临时表的建立和删除都会有较大的系统开销,而连接查询不会创建临时表,因此效率比嵌套子查询高.
索引是提高数据库查询速度最重要的方法之一,关于索引可以参高笔者一文,介绍比较详细,此处记录使用索引的三大注意事项:
- LIKE关键字匹配'%'开头的字符串,不会使用索引.
- OR关键字的两个字段必须都是用了索引,该查询才会使用索引.
- 使用多列索引必须满足最左匹配.
对于字段较多的表,如果某些字段使用频率较低,此时应当,将其分离出来从而形成新的表,
对于将大量连接查询的表可以创建中间表,从而减少在查询时造成的连接耗时.
类似于创建中间表,增加冗余也是为了减少连接查询.
分析表主要是分析表中关键字的分布,检查表主要是检查表中是否存在错误,优化表主要是消除删除或更新造成的表空间浪费.
1. 分析表: 使用 ANALYZE 关键字,如ANALYZE TABLE user;
- Op:表示执行的操作.
- Msg_type:信息类型,有status,info,note,warning,error.
- Msg_text:显示信息.
2. 检查表: 使用 CHECK关键字,如CHECK TABLE user[option]
option 只对MyISAM有效,共五个参数值:
- QUICK:不扫描行,不检查错误的连接.
- FAST:只检查没有正确关闭的表.
- CHANGED:只检查上次检查后被更改的表和没被正确关闭的表.
- MEDIUM:扫描行,以验证被删除的连接是有效的,也可以计算各行关键字校验和.
- EXTENDED:最全面的的检查,对每行关键字全面查找.
3. 优化表:使用OPTIMIZE关键字,如OPTIMIZE[LOCAL|NO_WRITE_TO_BINLOG]TABLE user;
LOCAL|NO_WRITE_TO_BINLOG都是表示不写入日志.,优化表只对VARCHAR,BLOB和TEXT有效,通过OPTIMIZE TABLE语句可以消除文件碎片,在执行过程中会加上只读锁.
- 配置多核心和频率高的cpu,多核心可以执行多个线程.
- 配置大内存,提高内存,即可提高缓存区容量,因此能减少磁盘I/O时间,从而提高响应速度.
- 配置高速磁盘或合理分布磁盘:高速磁盘提高I/O,分布磁盘能提高并行操作的能力.
优化数据库参数可以提高资源利用率,从而提高MySQL服务器性能.MySQL服务的配置参数都在my.cnf或my.ini,下面列出性能影响较大的几个参数.
- key_buffer_size:索引缓冲区大小
- table_cache:能同时打开表的个数
- query_cache_size和query_cache_type:前者是查询缓冲区大小,后者是前面参数的开关,0表示不使用缓冲区,1表示使用缓冲区,但可以在查询中使用SQL_NO_CACHE表示不要使用缓冲区,2表示在查询中明确指出使用缓冲区才用缓冲区,即SQL_CACHE.
- sort_buffer_size:排序缓冲区
更多参数传送门:
https://www.mysql.com/cn/why-mysql/performance/index.html
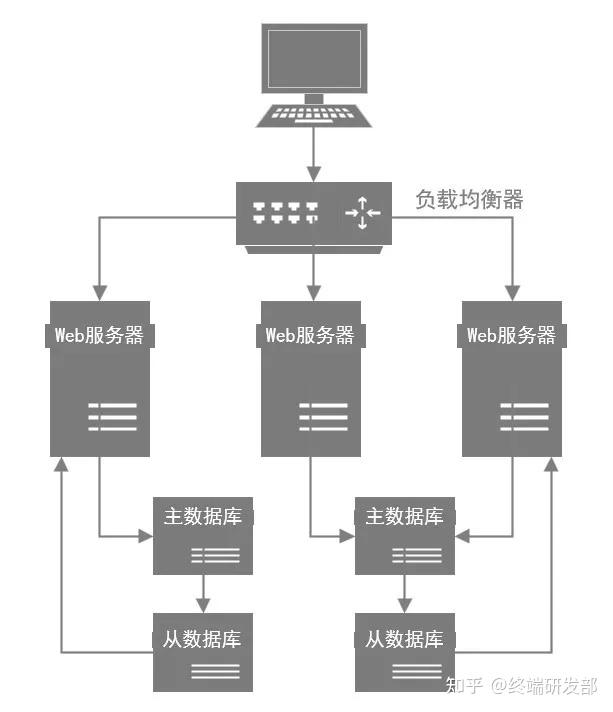
因为数据库压力过大,首先一个问题就是高峰期系统性能可能会降低,因为数据库负载过高对性能会有影响。另外一个,压力过大把你的数据库给搞挂了怎么办?
所以此时你必须得对系统做分库分表 + 读写分离,也就是把一个库拆分为多个库,部署在多个数据库服务上,这时作为主库承载写入请求。然后每个主库都挂载至少一个从库,由从库来承载读请求。
如果用户量越来越大,此时你可以不停的加机器,比如说系统层面不停加机器,就可以承载更高的并发请求。
然后数据库层面如果写入并发越来越高,就扩容加数据库服务器,通过分库分表是可以支持扩容机器的,如果数据库层面的读并发越来越高,就扩容加更多的从库。
但是这里有一个很大的问题:数据库其实本身不是用来承载高并发请求的,所以通常来说,数据库单机每秒承载的并发就在几千的数量级
而且数据库使用的机器都是比较高配置,比较昂贵的机器,成本很高。如果你就是简单的不停的加机器,其实是不对的。
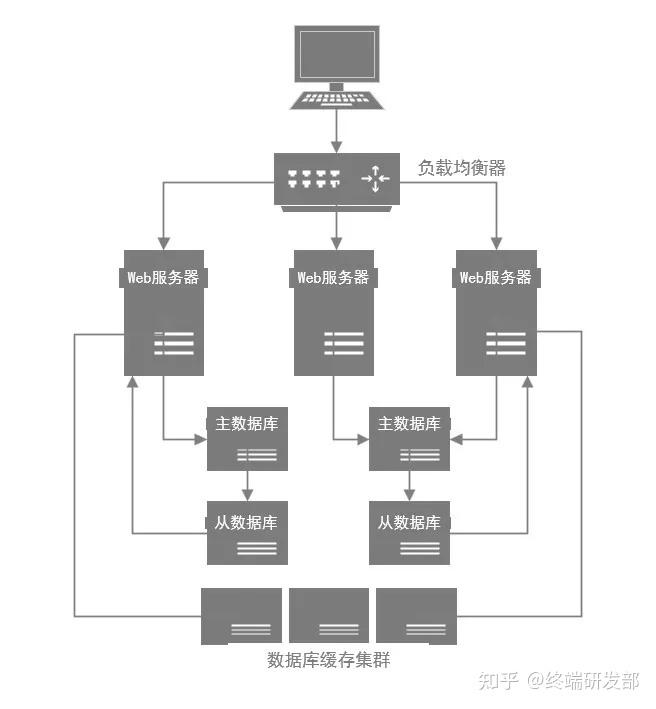
所以高并发架构里通常都有缓存这个环节,缓存系统的设计就是为了承载高并发而生。
所以单机承载的并发量都在每秒几万,甚至每秒数十万,对高并发的承载能力比数据库系统要高出一到两个数量级。所以你完全可以根据系统的业务特性,对那种写少读多的请求,引入缓存集群。
具体来说,就是在写数据库的时候同时写一份数据到缓存集群里,然后用缓存集群来承载大部分的读请求。
这样通过缓存集群,就可以用更少的机器资源承载更高的并发。
一个完整而复杂的高并发系统架构中,一定会包含:各种复杂的自研基础架构系统,各种精妙的架构设计。因此一篇小文顶多具有抛砖引玉的效果,但是数据库优化的思想差不多就这些了.
如果还不知道怎么去些许Mysql,可以参考这个帖子:
终端研发部:MySQL 批量插入,如何不插入重复数据?下面列出一些常用的SQl优化技巧,感兴趣的朋友可以了解一下。
1、注意通配符中Like的使用
以下写法会造成全表的扫描,例如:
select id,name from userinfo where name like '%name%'
或者
select id,name from userinfo where name like '%name'
下面的写法执行效率快很多,因为它使用了索引
select id,name from userinfo where name like 'name%'
2、避免在where子句中对字段进行函数操作
比如:
select id from userinfo where substring(name,1,6)='xiaomi'
或者
select id from userinfo where datediff(day,datefield,'2017-05-17') >=0
上面两句都对字段进行了函数处理,会导致查询分析器放弃了索引的使用。
正确的写法:
select id from userinfo where name like'xiaomi%'
select id from userinfo where datefield <='2017-05-17'
通俗理解就是where子句‘=’ 左边不要出现函数、算数运算或者其他表达式运算
3、在子查询当中,尽量用exists代替in
select name from userinfo a where id in(select id from userinfo b)
可以改为
select name from userinfo a where exists(select 1 from userinfo b where id=a.id)
下面的查询速度比in查询的要快很多。
4、where子句中尽量不要使用is null 或 is not null对字段进行判断
例如:
select id from userinfo where name is null
尽量在数据库字段中不出现null,如果查询的时候条件为 is null ,索引将不会被使用,造成查询效率低,
因此数据库在设计的时候,尽可能将某个字段可能为空的时候设置默认值,那么查询的时候可以
根据默认值进行查询,比如name字段设置为0,查询语句可以修改为
select id from userinfo where name=0
5、避免在where子句使用or作为链接条件
例如:
select id from userinfo where name='xiaoming' or name='xiaowang'
可以改写为:
select id from userinfo where name='xiaoming' union all
select id from userinfo where name='xiaowang'
6、避免在 where 子句中使用 !=或 <> 操作符。
例如:
select name from userinfo where id <> 0
说明:数据库在查询时,对 !=或 <> 操作符不会使用索引,
而对于 < 、 <=、=、 > 、 >=、 BETWEEN AND,数据库才会使用索引。
因此对于上面的查询,正确写法可以改为:
select name from userinfo where id < 0 union all
select name from userinfo where id > 0
7、少用in 或 not in
对于连续的数值范围查询尽量使用BETWEEN AND,例如:
select name from userinfo where id BETWEEN 10 AND 70
以上只是相对来说比较常用的sql优化技巧,当然还有很多欢迎补充!
https://zhuanlan.zhihu.com/p/372133621
https://zhuanlan.zhihu.com/p/377423102
参考:
https://www.cnblogs.com/prettyisshit/p/5841055.html https://www.cnblogs.com/hgmyz/p/12352792.html
前言
在应用开发的早期,数据量少,开发人员开发功能时更重视功能上的实现,随着生产数据的增长,很多 SQL 语句开始暴露出性能问题,对生产的影响也越来越大,有时可能这些有问题的 SQL 就是整个系统性能的瓶颈。
SQL 优化一般步骤
需要重点关注 type、rows、filtered、extra。
type 由上至下,效率越来越高:
- ALL 全表扫描
- index 索引全扫描
- range 索引范围扫描,常用语<,<=,>=,between,in 等操作
- ref 使用非唯一索引扫描或唯一索引前缀扫描,返回单条记录,常出现在关联查询中
- eq_ref 类似 ref,区别在于使用的是唯一索引,使用主键的关联查询
- const/system 单条记录,系统会把匹配行中的其他列作为常数处理,如主键或唯一索引查询
- null MySQL 不访问任何表或索引,直接返回结果
- 虽然上至下,效率越来越高,但是根据 cost 模型,假设有两个索引 idx1(a, b, c),idx2(a, c),SQL 为"select * from t where a=1 and b in (1, 2) order by c";如果走 idx1,那么是type 为range,如果走idx2,那么 type 是 ref;当需要扫描的行数,使用 idx2 大约是 idx1 的 5 倍以上时,会用 idx1,否则会用 idx2
Extra:
- Using filesort:MySQL 需要额外的一次传递,以找出如何按排序顺序检索行。通过根据联接类型浏览所有行并为所有匹配 WHERE 子句的行保存排序关键字和行的指针来完成排序。然后关键字被排序,并按排序顺序检索行;
- Using temporary:使用了临时表保存中间结果,性能特别差,需要重点优化;
- Using index:表示相应的 select 操作中使用了覆盖索引(Coveing Index),避免访问了表的数据行,效率不错!如果同时出现 using where,意味着无法直接通过索引查找来查询到符合条件的数据;
- Using index condition:MySQL5.6 之后新增的 ICP,using index condtion 就是使用了 ICP(索引下推),在存储引擎层进行数据过滤,而不是在服务层过滤,利用索引现有的数据减少回表的数据。
- 另外,推荐公众号Java精选,回复java面试,获取面试题资料,支持在线随时随地刷题。
了解 SQL 执行的线程的状态及消耗的时间。
默认是关闭的,开启语句“set profiling=1;”
SHOWPROFILES;
SHOWPROFILEFORQUERY#{id};
trace 分析优化器如何选择执行计划,通过 trace 文件能够进一步了解为什么优惠券选择 A 执行计划而不选择 B 执行计划。
setoptimizer_trace="enabled=on";
setoptimizer_trace_max_mem_size=1000000;
select*frominformation_schema.optimizer_trace;
如下:
- 优化索引
- 优化 SQL 语句:修改 SQL、IN 查询分段、时间查询分段、基于上一次数据过滤
- 改用其他实现方式:ES、数仓等
- 数据碎片处理
场景分析
索引:
KEY`idx_shopid_orderno`(`shop_id`,`order_no`)
SQL 语句:
select*from_twhereorderno=''
查询匹配从左往右匹配,要使用 order_no 走索引,必须查询条件携带 shop_id 或者索引(shop_id,order_no)调换前后顺序。
索引:
KEY`idx_mobile`(`mobile`)
SQL 语句:
select*from_userwheremobile=12345678901
隐式转换相当于在索引上做运算,会让索引失效。mobile 是字符类型,使用了数字,应该使用字符串匹配,否则 MySQL 会用到隐式替换,导致索引失效。
索引:
KEY`idx_a_b_c`(`a`,`b`,`c`)
SQL 语句:
select*from_twherea=1andb=2orderbycdesclimit10000,10;
对于大分页的场景,可以优先让产品优化需求,如果没有优化的,有如下两种优化方式:
- 一种是把上一次的最后一条数据,也即上面的 c 传过来,然后做“c < xxx”处理,但是这种一般需要改接口协议,并不一定可行
- 另一种是采用延迟关联的方式进行处理,减少 SQL 回表,但是要记得索引需要完全覆盖才有效果。
SQL改动如下:
selectt1.*from_tt1,(selectidfrom_twherea=1andb=2orderbycdesclimit10000,10)t2wheret1.id=t2.id;
索引:
KEY`idx_shopid_status_created`(`shop_id`,`order_status`,`created_at`)
SQL 语句:
select*from_orderwhereshop_id=1andorder_statusin(1,2,3)orderbycreated_atdesclimit10
in 查询在 MySQL 底层是通过 n*m 的方式去搜索,类似 union,但是效率比 union 高。
in 查询在进行 cost 代价计算时(代价=元组数 * IO 平均值),是通过将 in 包含的数值,一条条去查询获取元组数的,因此这个计算过程会比较的慢。
所以 MySQL 设置了个临界值(eq_range_index_dive_limit),5.6 之后超过这个临界值后该列的 cost 就不参与计算了。因此会导致执行计划选择不准确。
默认是 200,即 in 条件超过了 200 个数据,会导致 in 的代价计算存在问题,可能会导致 MySQL 选择的索引不准确。
处理方式:可以(order_status,created_at)互换前后顺序,并且调整 SQL 为延迟关联。
索引:
KEY`idx_shopid_created_status`(`shop_id`,`created_at`,`order_status`)
SQL 语句:
select*from_orderwhereshop_id=1andcreated_at>'2021-01-0100:00:00'andorder_status=10
范围查询还有“IN、between”。另外,更多关于SQL面试题,公众号Java精选,回复java面试,获取SQL语句面试题资料,支持在线随时随地刷题。
可以用到 ICP:
select*from_orderwhereshop_id=1andorder_statusnotin(1,2)
select*from_orderwhereshop_id=1andorder_status!=1
在索引上,避免使用 NOT、!=、<>、!<、!>、NOT EXISTS、NOT IN、NOT LIKE等。
如果要求访问的数据量很小,则优化器还是会选择辅助索引,但是当访问的数据占整个表中数据的蛮大一部分时(一般是 20% 左右),优化器会选择通过聚集索引来查找数据。
select*from_orderwhereorder_status=1
查询出所有未支付的订单,一般这种订单是很少的,即使建了索引,也没法使用索引。
selectsum(amt)from_twherea=1andbin(1,2,3)andc>'2020-01-01';
select*from_twherea=1andbin(1,2,3)andc>'2020-01-01'limit10;
如果是统计某些数据,可能改用数仓进行解决;如果是业务上就有那么复杂的查询,可能就不建议继续走 SQL 了,而是采用其他的方式进行解决,比如使用 ES 等进行解决。
select*from_twherea=1orderbybdesc,casc
desc 和 asc 混用时会导致索引失效。
对于推送业务的数据存储,可能数据量会很大,如果在方案的选择上,最终选择存储在 MySQL 上,并且做 7 天等有效期的保存。
那么需要注意,频繁的清理数据,会照成数据碎片,需要联系 DBA 进行数据碎片处理。
作者:狼爷
https://www.cnblogs.com/powercto/p/14410128.html
公众号“Java精选”所发表内容注明来源的,版权归原出处所有(无法查证版权的或者未注明出处的均来自网络,系转载,转载的目的在于传递更多信息,版权属于原作者。如有侵权,请联系,笔者会第一时间删除处理!
------ THE END ------
微信小程序>Java精选面试题<3000+ 道面试题在线刷,最新、最全 Java 面试题!
最近有很多人问,有没有读者交流群!想知道如何加入?方式很简单,兴趣相投的朋友,只需要点击下方卡片,回复“加群”,即可无套路入交流群!
文章有帮助的话,在看,转发吧!
可以看看《高性能MySQL》,也可以看看我这篇文章,算是这本书的一个精华总结。
SQL优化,算是数据库优化的一个子集。
因此,吹大牛的候选人简历上,会赫然写着”擅长MySQL数据库优化“,而吹小牛的候选人简历上,往往会写”擅长SQL优化“。
但结局是殊途同归的,就是当问他们用什么方式做的优化,他们都会说上三个字:”加索引“。
当然,好一点儿的会说可以加联合索引,它有最左前缀匹配原则(8.0以后的版本就不完全对了)之类的,还能说说覆盖索引。
那么,我的这篇文章,就好好聊聊这个面试话题。
先教大家一个小窍门,最好大家在回答面试官这个问题的时候,最好可以做到跟自己简历中项目的进行真实场景带入,这样会给面试官一种可以理论结合实践的感觉,是个大大的加分项。
举个例子,话术为:
“当时我负责电商平台的商品中心优化,我发现在展示商品列表的时候,一旦深分页就会出现加载缓慢的问题,然后我就看了一下对应的SQL语句,是这样写的:
select id, name, status, detail from product limit 10, 30;
那么一旦在深分页的话,SQL语句就会变成这样:
select id, name, status, detail from product limit 100000, 30;那么MySQL的执行方式为:一共需要查100030条数据,然后丢弃前面的100000条,只返回后面的30条数据,这样做是非常浪费资源的。
于是我把SQL改为:
select id, name, status, detail from product where id > 100000 limit 30;
100000为上次分页中最大的商品ID,先找到它,然后再根据主键ID扫描后续30条数据。
这样做性能很高,把SQL语句从原先的耗时4300ms,降低到了18ms。”
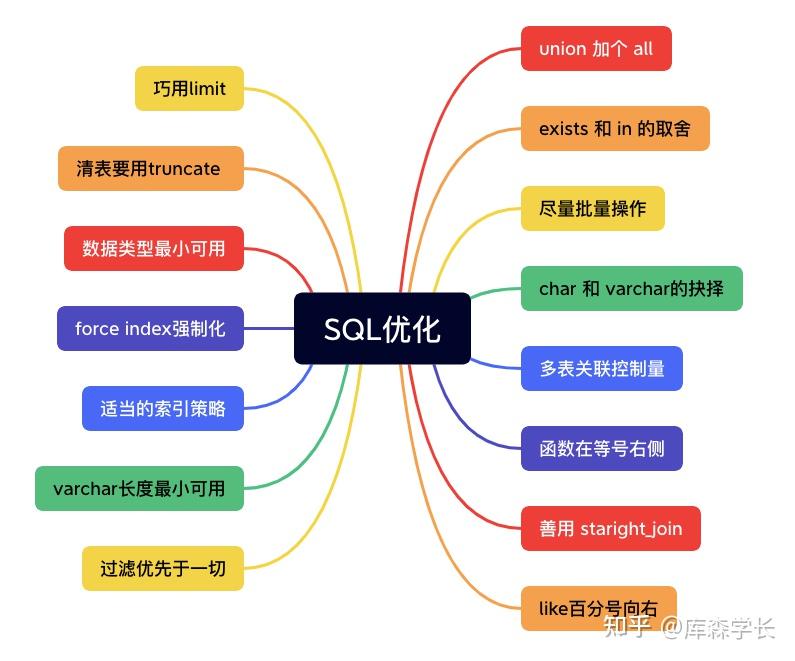
好了,下面我正式给大家列举一下,SQL优化的N种技巧,select * 这种的就不写了哈。
上文已经讲解了,仔细看下即可。
反例:
select * from employee where address like '%通州区%';
select * from employee where address like '%通州区';正解:
select * from employee where address like '北京市通州区%';原因:
(1)全模糊查询,或者左边出现%的模糊查询,会导致索引实效,应该尽量从查询方式或表结构设计上避免。
(2)若无法避免,且数据量庞大的情况下,一定要使用ElasticSearch进行替代。
反例:
select product_id from orders where id=100
union
select product_id from orders where id=200;
正解:
select product_id from orders where id=100
union all
select product_id from orders where id=200;原因:
union:对两个结果集进行并集操作,不包括重复行,相当于distinct,同时进行默认规则的排序;
union all:对两个结果集进行并集操作,包括重复行,不进行排序;
union因为要进行重复值扫描,所以在结果集庞大的情况下,效率极低,因此建议使用union all。
若结果集去重是强需求,则在应用程序代码上进行去重,因为数据库资源要比应用服务器资源更加珍贵。
straight_join功能同inner join类似,但能让左边的表来驱动右边的表,通过改变优化器对于联表查询的执行顺序的方式,获取更好的性能。
btw:若驱动表(左边)的数据量小于(被驱动表),它的执行性能要高于,驱动表(左边)的数据量大于(被驱动表)。
举个例子:
select * from t2 straight_join t1 on t2.a=t1.a;比如上面这个,如果我们事先知道t2表的数据量一定小于t1表的话,就可以使用上面的方式指定t2表为驱动表。
需要注意的点:
(1)straight_join只适用于inner join,并不适用于left join,right join。
(2)大部分情况下,MySQL优化器是可以做出正解的。因此,使用straight_join一定要慎重,因为部分情况下人为指定的执行顺序并不一定会比优化引擎要靠谱。
select * from student where school_id in (select id from school);
select * from police p where exists (select 1 from user u where u.id=p.id);如果子查询得出的结果集数据较少,主查询中的表较大且又有索引时,应该用in;反之,如果外层的主查询数据较少,子查询中的表大,又有索引时使用exists。
- 如果是exists,那么以外层表为驱动表,先被访问。
- 如果是in,那么先执行子查询。
in 是把外表和内表作 hash 连接,而 exists 是对外表作 loop 循环,每次 loop 循环再对内表进行查询。所以,我们会以驱动表的快速返回为目标,目标是以小表驱动大表,这是性能优化的本质。
之前有一种比较扯淡的说法,“exists 比 in 效率高”,大家试想一下,如何一个事物在任何场景下,都优于另外一个事物,那另外一个事物就没有存在的必要性了。
反例:
delete from user;正解:
truncate user;原因:
(1)truncate是直接把表删除,然后再重建表结构,性能很高,但删除操作记录不记入日志,不能回滚。
delete语句执行删除的过程是每次从表中删除一行,性能较低,但该行的删除操作会作为事务记录在日志中保存,以便进行进行回滚操作。
(2)truncate后,表和索引所占用的空间会恢复到初始大小,而delete只是将被删除的记录标记为已删除,不会立即减少表或索引所占用的空间。
反例:
insert into student(name, sex, age) values('Tom', 1, 20);
insert into student(name, sex, age) values('Tony', 1, 18);正解:
insert into student(name, sex, age) values('Tom', 1, 20), ('Tony', 1, 18);原因:
SQL批量操作,即一次数据库操作中插入多个数据行,相比于单条插入,可减少大量的IO交互和SQL解析开销,从而提高了插入效率。
反例
select city, avg(area) from country group by city having city='beijing' or city='shanghai';
正解:
select city, avg(area) from country where city='beijing' or city='shanghai' group by city;原因:
记住,无论是分组还是排序,或者多表join,如果可以的话,第一件事就是把用不到的记录先过滤掉。
反例:
select * from article where left(title, 4)='环球资讯';
正解:
select * from article where title=left('环球资讯', 4);
原因:
如果在索引列上使用函数,会导致索引实效。
一般情况下,应该尽量使用可以正确存储数据的最小数据类型。更小的数据类型通常会使SQL执行更快,因为它们占用更少的磁盘、内存和CPU缓存,并且处理时需要的CPU周期也更少。
但是,要确保没有低估需要存储的值的范围,因为在表schema中修改数据类型是一件非常耗时和痛苦的操作(特指表数据量很大的场景)。如果无法确定哪个数据类型是最好的,就选择你认为不会超过范围的最小类型。
举个例子:如果确定只需要存0—200,tinyint unsigned类型是最适合的。
char:定长,存取效率高,一般用于固定长度的表单提交数据存储,例如:身份证号,手机号,电话,密码等,长度不够的时候,会采取右补空格的方式。
varchar:不定长,更节省空间,需要用一个或者两个字节来存储数据的长度。具体规则是:如果列的最大长度小于或等于255字节,则只使用1个字节表示,否则使用2个字节。
varchar由于行是变长的,在UPDATE时可能使行变得比原来更长,会导致分裂页和产生碎片。
有人认为,既然varchar是变长的,那我就尽量给它设置得大一些,以备不时之需,反正没有坏处。
其实,varchar(5) 和 varchar(200)是不一样的!
我们看下《高性能MySQL》一书中的原话:
因此,当你把varchar的长度调整为最小可用,是可以帮助你优化SQL排序性能的。
- 频繁作为查询条件的字段应该创建索引,频繁更新的字段不适合创建索引;
- 多表关联查询中的关联字段,查询中统计或者分组字段,查询中排序字段,应该创建索引;
- 尽量使用数据量少或区分度高的字段创建索引;
- 多条件组合查询优先创建组合索引,熟悉组合索引的最左前缀原则,不要创建冗余索引;
- 禁止使用全文索引,可以用前缀索引进行替代;
- 善于利用覆盖索引来优化查询;
- delete和update语句的where条件必须由索引,否则会导致锁表;
适当的索引策略,经过业务取舍后,可以使SQL执行得更快。
MySQL查询优化器在执行SQL语句时,会选择它认为最合适的索引,但有时却并不准确,不是实际上最快的索引,此时可以用force index人为指定索引。
force index 跟着表名后面,用于强制使用指定的索引名(key)。
如下列所示:
select * from msg force index(idx_dest_src) where dest='18736809673' and src in ('15144804019', '18674654894');据说,阿里巴巴开发者手册规定,join表的数量不应该超过3个,这个我还真没看到。
我个人觉得,多表关联需要控制量,但没必要完全一杆子拍死。
如果某个系统中,有很多多表关联的大SQL,那确实意味着表结构设计有问题,或者需要引入ES等技术方案了。
整体就这么多,后续如果有新的,我再补充。